【テキストマイニング研究室:第5回】 係り受けのむずかしさ
.png?w=30)
【テキストマイニング研究室】では、見える化エンジンのコア技術であるテキストマイニングに関連した技術について詳しく解説していきます。
▼これまでのテキストマイニング研究室はこちら
https://note.com/mierukaengine/m/mb715c8c30ba3
今回は、「係り受けのむずかしさ」 についてご紹介します。
第5回のテーマ…“係り受けのむずかしさ”
第2回では、係り受け解析(=構文解析)をご紹介しましたが、
今回は、そのむずかしさの一端をご紹介します。
日本語文法の基本原則:連用と連体
日本語の係り受け文法の基本は、
- 文の前方から後方に係る
- 連用修飾句は用言に係る
- 連体修飾句は体言に係る
という3点に尽きます。簡単明瞭ですね!
「すっごい美味しい!」と普通に言いますが、ちょっとたどたどしく聞こえるのは、「すっごい」が連体形なのに「美味しい」という形容詞(用言)に係っているからです。
この文には他に係り先となる単語がないのでこれでも解析できますが、文法的には間違いと言えます。
だったら、文法的に正しければ連用・連体の原則だけで機械的に係り受けができるかというと、そう単純でもありません。
コンピュータにとってどんな場合がむずかしいのか、見ていきましょう。
連用・連体の判断がつきにくい時
実は連体・連用の両方に使える助詞がいくつかあります。しかもよく使う助詞です。
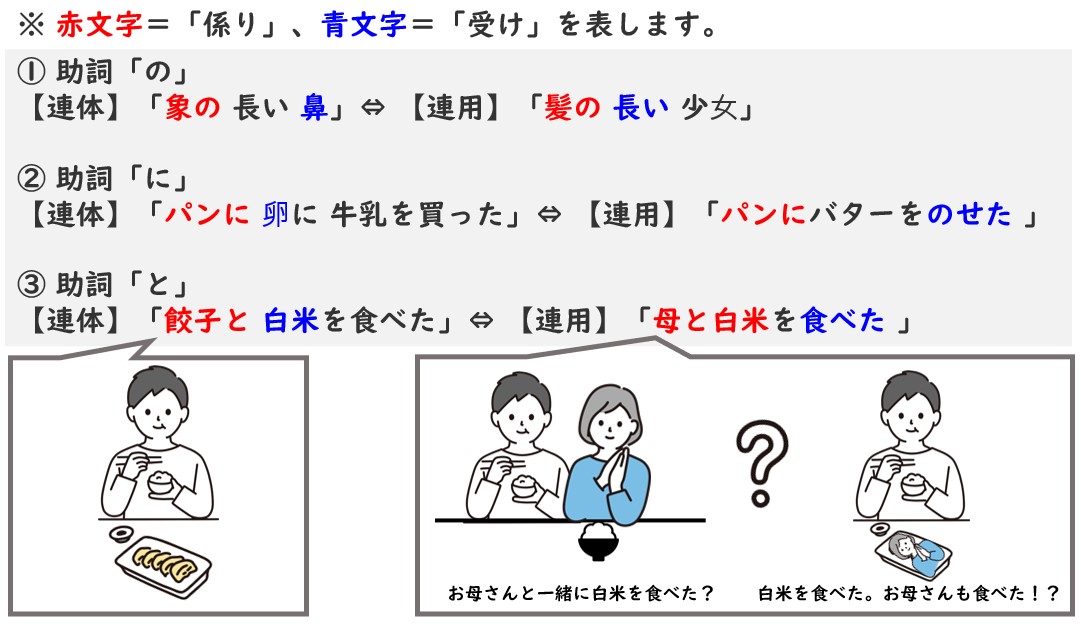
これらは品詞の並びとしてはほぼ同じなので、文法的には区別することが困難です。
正しい係り受けを得るためには、文法以外の「知識」が必要になります。
並列句を「知識」で解く
上の②と③の【連体】は「並列句」と呼ばれるもので、昔から係り受け解析の難問でした。
こういう時には、前回ご紹介した単語(語義)の分類体系が役に立ちます。
【冷麺と焼肉を食べた。 ⇔ 母と焼肉を食べた。】
分類体系の枝分かれ図をたどると、
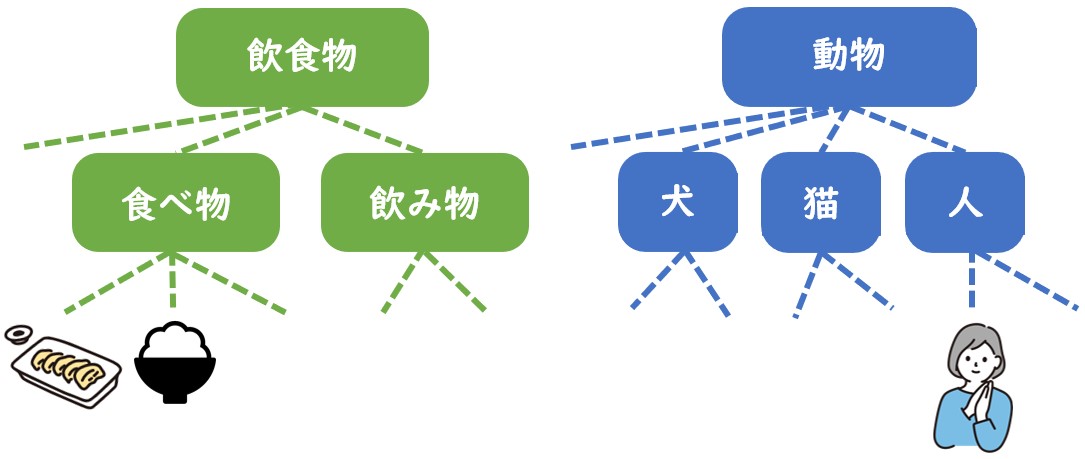
「冷麺」と「焼肉」は『食物』のカテゴリーの中で近いところにある!
「母」と「焼肉」は、はるかに遠いところにある!
ということがわかります。
「○○と△△」が並列句であるためには、言葉の種類が似ているということが必要なので、「母」と「焼肉」は並列句になりにくいということになるわけです。
係り先の候補がたくさんある時
最初に挙げた3原則に「前方から後方に係る」というのがありました。
ちょっと長い文では、修飾句の後方に複数の受け候補があるということはよくあります。

「スマホで-走る」よりも「スマホで-撮る」の方が自然だということは、
人ならすぐわかりますが、文法だけでは区別することができません。
コンピュータでは「用例」がその判断に役立ちます。
WEB上に日々出現する膨大な文章を解析して、「○○を食べる」「△△で撮る」といった用例を大量に収集できるようになりました。
そうした用例の頻度に基づいて最も自然な係り受けを判定することが可能になってきています。
まとめ
コンピュータによる係り受け解析は、こんな情報を手がかりにして行われています。
- 文法的な連体、連用の判断
- 文の大きな切れ目(読点、接続助詞「ので、から、たら、…」、など)
- 文法以外の知識(単語の分類体系や用例のデータ)の利用
とはいえ、言葉の「知識」はこれだけではありません。
わたしたちが「常識」と思っているものはとても多様で、理屈では表現しにくいものがまだまだあります。
自然言語処理の課題はなかなか尽きることがありません。
---------
担当:住谷・高井・小山